Qu'est ce que l'Intelligence Artificielle, le Machine Learning, le Deep Learning ?

Comment s'y retrouver avec toutes ces innovations technologiques qui bouleversent nos organisations ? L'intelligence artificielle, le Machine Learning et le Deep Learning sont des nouveaux moyens rapides de traiter l'information ayant quand même quelques limites.
Intelligence Artificielle, Machine Learning et Deep Learning
L'intelligence artificielle (Artificial Intelligence) est l'ensemble des technologies de traitement de l'information visant à conférer des capacités cognitives comparables à celle des humains à des ordinateurs, machines ou robots, grâce à des fonctions mathématiques, des algorithmes mais aussi des modes de représentation de l'environnement réel. Cette discipline scientifique s'est structurée dès le début des années 1950, avec l'article séminal d'Alan Turing : « Computing Machinery and Intelligence » dans lequel il considère la question « Les machines peuvent-elle penser ? » ou l'utilisation du terme d'Artificial Intelligence par John McCarty et Marvin Minsky (1956).
Deux grandes approches
On distingue généralement deux grandes approches en IA :
- les approches symbolistes, où les connaissances et le raisonnement sont représentés par une formulation ou une logique mathématique (avec des symboles)
- les approches connexionnistes, où la fonction cognitive est réalisée par l'assemblage de neurones formels, mathématiques, connectés entre eux dans des réseaux plus ou moins complexes (réseaux de neurones)
Les approches symbolistesont pour avantage de représenter explicitement les connaissances utilisées et le raisonnement réalisé (ex. : faire un diagnostic à partir de règles élicitées par un médecin spécialiste), ce qui confère de bonnes capacités d'explications des résultats obtenus, donc de validation et de confiance dans les capacités de l'outil.
Les approches connexionnistes utilisent une étape d'apprentissage à partir de données pour adapter itérativement (la phase d'apprentissage) la configuration et les liens au sein du réseau de neurones au problème à résoudre (ex. : identifier un chat dans une image, calculer l'angle de braquage des roues d'un véhicule en fonction du flux vidéo de la route). La performance de ces approches se fait au dépend de l'explicabilité du raisonnement produit.
Des tentatives de rapprocher les deux approches sont actuellement à l'étape de recherche, dans l'espoir de bénéficier des avantages de chacune des approches. D'autres cherchent à comprendre et rendre interprétables le comportement des réseaux de neurones.
Apprentissage automatique (Machine Learning)
Face aux difficultés rencontrées par les approches symbolistes de formaliser des raisonnements robustes dans un monde réel avec de nombreuses exceptions, et aussi grâce à l'opportunité que représentent les données accumulées (big data), apprendre des fonctions cognitives à partir des données devient une option prometteuse. C'est tout l'enjeu de l'apprentissage automatique (machine learning). Turing avait indiqué dans son premier article que la capacité d'apprendre serait clé pour les machines intelligentes, tout comme elle l'est pour les êtres humains.
L'apprentissage automatique repose sur un raisonnement inductif à partir des données : en partant d'observations, et de l'observation de régularités (patterns), on établit des règles générales recouvrant ces observations. Selon la technologie de machine learning utilisée, ces règles générales peuvent être des modèles mathématiques « classiques » (régressions linéaires par exemple), des règles logiques (si pain et fromage alors vin rouge) ou des réseaux de neurones entraînés.
Les développements récents du machine learning font apparaître deux usages différents :
- l'apprentissage statistique, tel que présenté ci-avant, pour modéliser une fonction. Cet usage se retrouve dans toute l'industrie des modèles : comportement (score d'appétence, d'attrition, etc.), prévision (des ventes, de flux, etc.), détection d'anomalie (lutte contre la fraude, maintenance préventive, etc.)
- l'apprentissage de programme, utilisé particulièrement dans les applications d'autonomie (robotique, véhicule autonome), où l'objectif est d'apprendre un programme plutôt que de le faire spécifier pas un humain. On parle alors de « Software 2.0 », le machine learning remplaçant les développeurs pour créer un programme.
L'apprentissage par renforcement est une autre technique pour apprendre un comportement par essai-erreur dans une simulation d'un environnement.
Les familles de problème d'apprentissage
On distingue habituellement deux grandes familles de problèmes :
- les apprentissages dits supervisés : pour ce type de problème, on dispose d'une variable cible dont on souhaite prédire la valeur à partir des données dont on dispose en entrée (appelées variables d'entrée du modèle, facteurs, attributs, ou features) et on cherche les meilleurs paramètres du modèle pour commettre l'erreur la moindre possible sur l'ensemble des observations.
- les apprentissages non supervisés : à partir d'un tableau de données décrivant des observations (ex. : des clients), il s'agit d'identifier des groupes homogènes au sein de la population.
Le tableau suivant récapitule les principaux algorithmes disponibles pour chaque famille, selon le type de problème à traiter et leurs applications marketing.
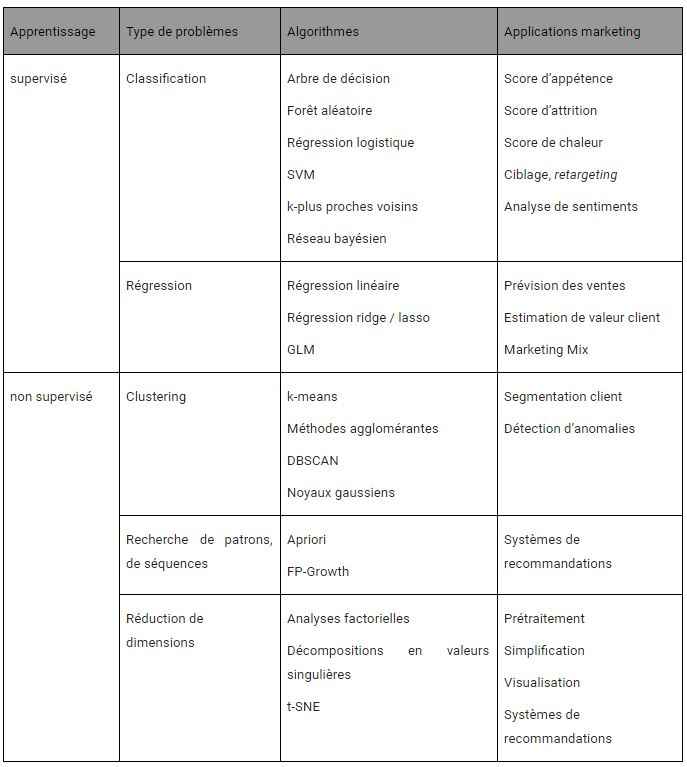
Les réseaux de neurones ne figurent pas dans ce tableau car ils sont utilisés pour quasiment tous les types de problèmes, dans diverses formes (architecture, représentation des données).
Réseaux de neurones & deep learning
Les réseaux de neurones sont une technique ancienne (dès les années 1940) mais trois facteurs ont conduit à son développement actuel depuis le milieu des années 2000 et contribuent aux succès impressionnants du deep learning :
- la disponibilité de gisements de données très importants,
- le développement de nouveaux algorithmes et de nouvelles architectures (profondeur des réseaux en nombre de couches, réseaux à convolutions, CNN ; réseaux récurrents),
- des capacités de calcul conséquentes avec du matériel dédié (processeurs graphiques ou 'Graphical Processing Units', GPU et spécialisés : Tensor Processing Units, TPU).
Des limites à l'intelligence artificielle et des réseaux de neurones profonds
Les succès récents du deep learning ont conduit à des affirmations tout à fait exubérantes quant aux capacités de l'intelligence artificielle. Les résultats actuels concernent une intelligence artificielle spécialisée (en environnement contrôlé, pour un sujet bien défini) et sont bien loin d'une intelligence artificielle générale, comme celle de l'humain.
Les réseaux de neurones présentent des limitations, dont conviennent des spécialistes du domaine, pour certains à l'origine du deep learning (Yoshua Bengio, prix Turing 2018).
Gary Marcus recense ainsi dix points sur lesquels les réseaux de neurones sont conceptuellement limités dont :
- le besoin d'une quantité de données très importante pour apprendre, ce qui n'est pas disponible pour tous les problèmes,
- les possibilités de tromper le modèle une fois entrainée (spoofability), introduisant des incertitudes dans leur fiabilité à l'usage,
- l'absence d'explications sur la conclusion produite par le réseau ainsi que son niveau de confiance dans le résultat obtenu
Un consensus se dégage autour du fait que ce sont des limites conceptuelles que les réseaux profonds ne pourront pas franchir. Il convient donc d'orienter dès à présent les recherches sur des approches hybrides, ou de découvrir ou redécouvrir d'autres algorithmes pour faire progresser l'intelligence artificielle.
Auteur
Cette réponse vous a été apportée par Hervé Mignot, Associé en charge de la R&D, data science et technologies - Equancy, Membre du Turing Club



